CPU Subsystem
This chapter describes the implementation-specific options of the TC1.6.2P TriCore™ CPUs found in the AURIX™ series of devices. It gives an overview of variant topics, including CPU features like architectural overview, programming models, CPU registers, tasks and functions, etc.
Feature List
The CPU comes with a variety of high-performance features, which include a 32-bit load store architecture, 4 Gbyte address range (232), 16-bit and 32-bit instructions for reduced code size, as well as lists with various data types and data formats used in connection with the CPU deployment.
The TC1.6.2P Implementation allows most instructions executed in 1 cycle. Branch instructions are executed in 1, 2 or 3 cycles (using dynamic branch prediction). A wide memory interface allows fast context switch. Furthermore, an automatic context save-on-entry and restore-on-exit build the basis for subroutine, interrupt, trap, etc. Six memory protection register sets and a dual instruction issuing (in parallel into Integer Pipeline and Load/Store Pipeline) are additional features.
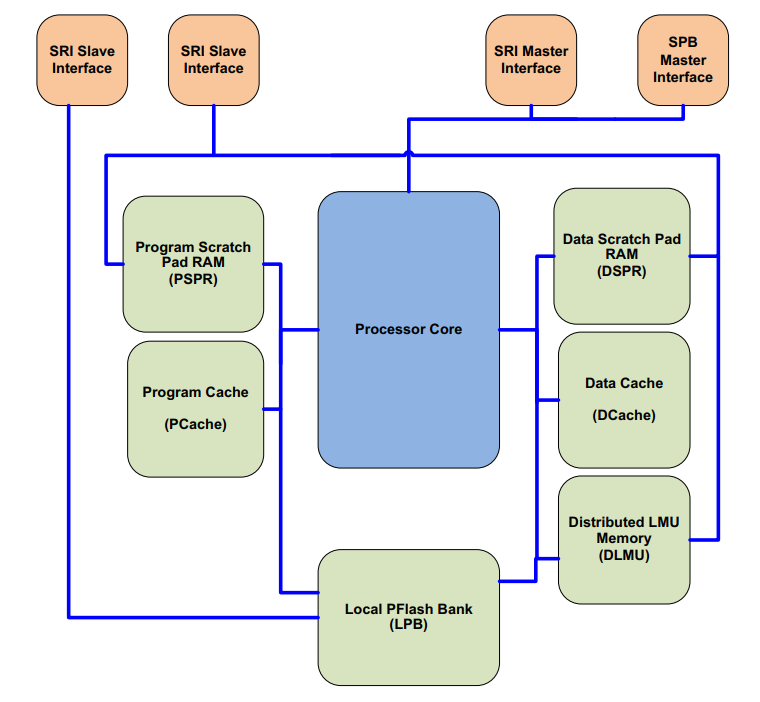
The processor core connects to memories and bus interfaces like Data Scratchpad SRAM (DSPR), Program Scratchpad SRAM (PSPR), Data Cache (DCache), Program Cache (PCache), Distributed LMU memory (DLMU), etc.
Functional description
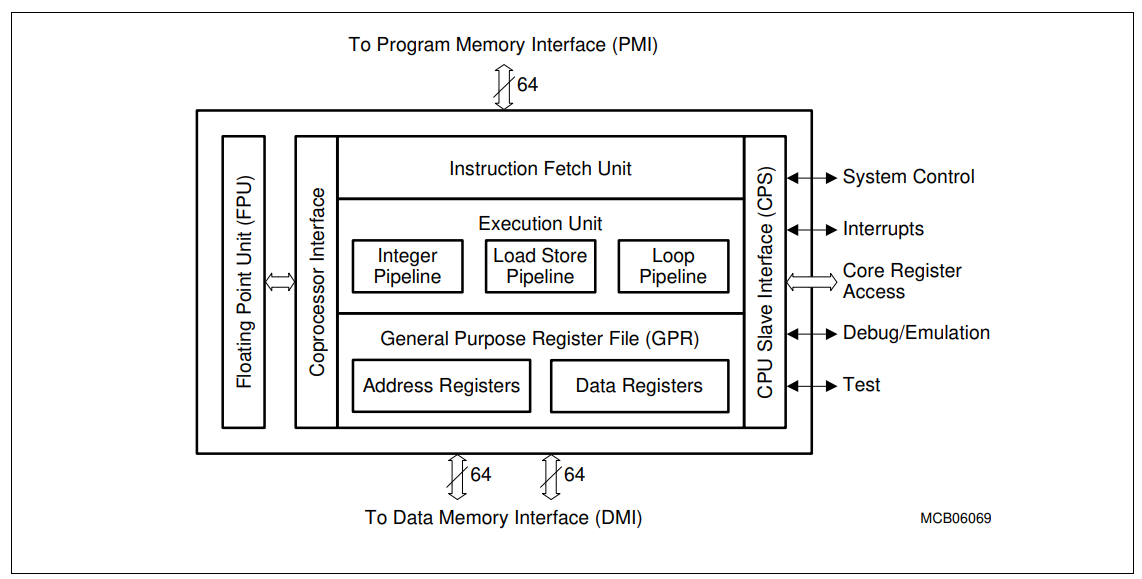
The Central Processing Unit (CPU) comprises of the following:
- Instruction Fetch Unit (IFU)
- Execution Unit
- General Purpose Register File (GPR)
- CPU Slave interface (CPS)
- Floating Point Unit (FPU)
Instruction Fetch Unit (IFU)
The Instruction Fetch Unit pre-fetches and aligns incoming instructions from the 64-bit wide Program Memory Interface (PMI). Instructions are placed in predicted program order in the Issue fifo. The Issue fifo buffers up to six instructions and directs the instruction to the appropriate execution pipeline. The Instruction Protection Unit checks the validity of accesses to the PMI and the integrity of incoming instructions fetched from the PMI. The branch unit examines the fetched instructions for branch conditions and predicts the most likely execution path based on previous branch behavior. The Program Counter Unit (PC) is responsible for updating the program counters.
Execution Unit
The Execution Unit contains the Integer Pipeline, the Load/Store Pipeline and the Loop Pipeline. All three pipelines operate in parallel, permitting up to three instructions to be executed in one clock cycle. In the execution unit all instructions pass through a decode stage followed by two execute stages. Pipeline hazards (stalls) are minimised by the use of forwarding paths between pipeline stages allowing the results of one instruction to be used by a following instruction as soon as the result becomes available.
General Purpose Register File (GPR)
The CPU has a General Purpose Register (GPR) file, divided into an Address Register File (registers A0 through A15) and a Data Register File (registers D0 through D15). The data flow for instructions issued to the Load/Store Pipeline is steered through the Address Register File. The data flow for instructions issued to/from the Integer Pipeline and for data load/store instructions issued to the Load/Store Pipeline is steered through the Data Register File.